■ 비선형 자료구조 - 트리(Tree)
우리가 여태까지 다룬 자료구조(배열, 리스트, 스택, 큐, 덱)는 각 데이터가 앞 뒤로 하나의 데이터와만 연결되는 구조를 가지는 “선형 자료구조”였다.
이번 장에서 설명할 트리(Tree)는 하나의 데이터가 여러 개의 하위 데이터를 가질 수 있는 구조로, 계층적인 관계(Hierarchical Relationshipe)를 표현하는 비선형 자료구조인 트리에 대해 살펴보자.
자료구조를 단순히 “저장하고 꺼내는 도구”로 이해하기 쉽지만, 자료구조의 본질은 어떤 대상을 구조적으로 표현하는 도구이다.
- 따라서, 트리의 추상 자료형(ADT)을 정의할 때도 “저장과 삭제가 편리한가?”보다 “계층 구조를 표현하기에 적절하게 정의되었는가?”의 관점에서 바라보는 것이 옳다.
1. 트리의 표현
트리도 우리 주변에서 쉽게 예시를 찾을 수 있는 자료구조이다. 폴더 구조나 집안의 족보 혹은 기업 및 정보의 조직도로 트리의 예시를 들 수 있다.

나무처럼 보이진 않지만, 이 자료구조에 트리라는 이름이 붙은 이유는 “가지를 늘려가며 뻗어나간다”라는 공통점이 있기 때문이다.

위와 같은 트리를 “의사 결정 트리(Decision tree)”라 한다. 의사 결정 트리는 다양한 데이터 분석 기법의 도구가 되며, 경영학 등 공학 이외의 영역에서도 유용하게 사용된다.
이처럼 트리를 이용해 무엇을 저장하고 꺼내야 한다는 생각을 지우고, 무엇을 표현하는 도구라고 생각하자.
2. 트리 용어
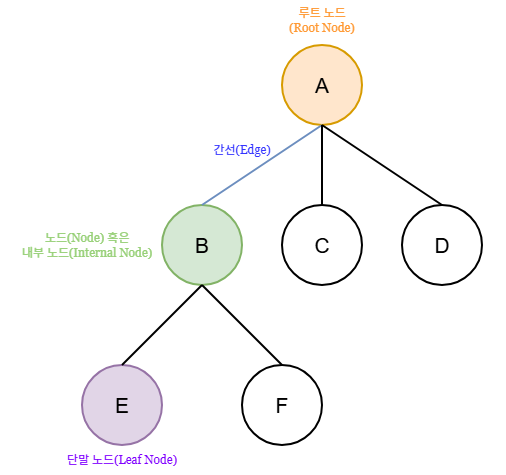
- 노드(Node)
- 트리의 구성 요소에 해당하는 A, B, C, D, E, F와 같은 요소.
- 간선(Edge)
- 노드와 노드를 연결하는 연결선
- 루트 노드(Root Node)
- 트리의 최상단에 존재하는 A와 같은 노드.
- 단말 노드(Leaf Node/Terminal Node)
- 아래로 또 다른 노드가 연결되어 있지 않은(자식이 없는) C, D, E, F와 같은 노드.
- 다른 표현으로 Terminal Node라고 불리지만, Leaf Node라는 표현이 더 많이 쓰인다.
- 내부 노드(Internal Node)
- 단말 노드를 제외한 모든 노드.

또한 위처럼 트리의 노드 간에는 부모(parent), 자식(child), 형제(sibling)의 관계가 성립된다.

트리에서는 루트 노드부터 각 층별로 숫자를 매겨 이를 트리의 “레벨”이라고 하고, 트리의 최고 레벨을 가리켜 “높이”라 한다.
■ 이진트리(Binary Tree)와 서브 트리(Sub Tree)

큰 트리는 작은 트리로 구성이 되고, 큰 트리에 속하는 작은 트리를 가리켜 “서브 트리(Sub Tree)” 라 한다.
- 서브 트리의 아래에는 더 작은 서브 트리가 존재한다.

위 그림에서 보이는 트리가 중점을 두어 살펴보고 구현할 “이진트리(Binary tree)”이다. 이진트리를 간단하게 설명하자면 자식 노드가 두 개씩 달린 트리를 의미한다. 자세한 조건은 다음과 같다.
- 루트 노드를 중심으로 두 개의 서브 트리로 나뉜다.
- 나뉜 두 서브 트리도 모두 이진트리이어야 한다.

노드가 위치할 수 있는 곳에 노드가 존재하지 않는다면, 공집합(empty set) 노드가 존재하는 것으로 간주할 수 있다. 물론 공집합 노드도 이진트리의 판단에 있어서 노드로 인정하기에, 위와 같은 형태의 트리도 이진 트리라 볼 수 있다.
이처럼 이진 트리의 폭은 생각보다 넓고, 이에 따라 이진트리도 특성에 따라 세분화된다.
1. 포화 이진(Full Binary) 트리와 완전 이진(Complete Binary) 트리

위의 이진트리는 모든 레벨이 꽉 차있다. 노드를 더 추가하려면 레벨을 늘려야 하는데, 이렇게 레벨이 모두 꽉 찬 이진트리를 가리켜 “포화 이진트리”라 한다.
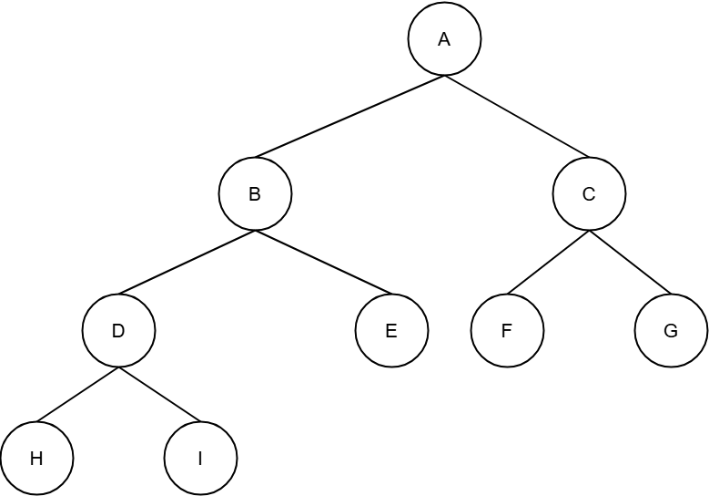
포화 이진트리처럼 레벨이 꽉 찬 상태는 아니지만, 빈 틈 없이 채워진 트리를 가리켜 “완전 이진트리”라 한다. 여기서 말하는 “빈 틈 없이 채워진 트리”가 가지는 의미는,
- 노드가 위에서 아래로, 왼쪽에서 오른쪽의 순서대로 채워졌다!
를 의미한다.
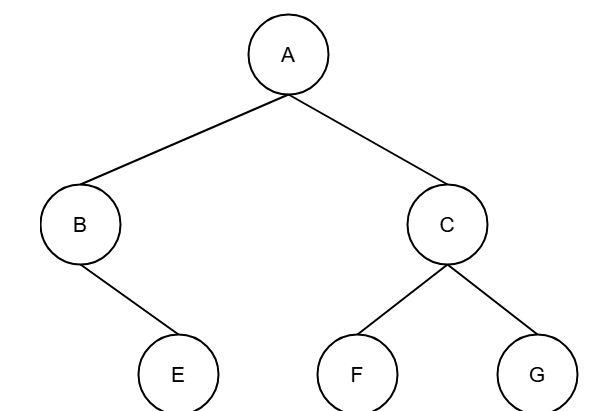
참고로 이런 트리는 이진트리의 조건에는 부합하지만, 포화도 완전도 아닌 그냥 이진트리이다.
■ 이진트리의 구현
이진트리는 재귀적인 특성을 지니고 있어서 어느정도 재귀 함수에 익숙해야 구현하는데 큰 어려움이 없을 것이다.
1. 배열 기반? 리스트 기반?
이진 트리 역시 배열 기반으로도, 연결 리스트 기반으로도 구현이 가능하다. 트리를 표현하기엔 연결 리스트가 더 유연하기 때문에 대부분은 연결 리스트를 기반으로 구현할 것이다.
하지만 완전 이진트리의 경우, 트리가 완성된 이후부터는 그 트리를 대상으로 매우 빈번한 탐색이 일어나기에 탐색이 용이한 배열 기반으로 먼저 살펴보자.

배열을 기반으로 이진트리를 구현하려면, 각 노드에 번호를 구현해야 한다. 이 번호가 의미하는 바는, 각 노드의 데이터가 저장되어야 할 배열의 인덱스 값을 의미한다.

길이가 8인 배열을 선언하여 노드 번호 1~5까지 노드에 저장된 데이터를 배열에 저장한 결과이다. 번호가 1인 루트 노드의 데이터 A는 인덱스가 1인 위치에 저장되었고, 번호가 3인 노드의 데이터 C는 3인 위치에 저장되었다.
- 인덱스 0은 사용하지 않는 편이 구현의 편의와 실수할 확률을 낮추기 때문에 사용하지 않는다.

그림으로 봐도 리스트 기반의 구현 방식이 바로 이해될 수 있다. 사실 연결 리스트의 구성 형태가 트리와 일치하기 때문이다.
2. 헤더 파일 정의
#pragma once
using BData = int;
struct BNode
{
BData data;
BNode* left = nullptr;
BNode* right = nullptr;
};
BData GetNodeData(BNode* node);
void SetNodeData(BNode* node, BData data);
BNode* GetLeftSubTree(BNode* node);
BNode* GetRightSubTree(BNode* node);
void MakeLeftSubTree(BNode* main, BNode* sub);
void MakeRightSubTree(BNode* main, BNode* sub);
[BinaryTree.h]
이진트리를 구현하기 위해서는 각 노드를 표현하는 구조체 하나만으로도 기본적인 트리 구조를 구성할 수 있다.
그렇다면, 이진 트리를 표현한 구조체는 정의하지 않아도 될까?
- 앞서 리스트 기반 큐를 구현할 때는 노드를 표현한 구조체와 큐를 표현한 구조체를 각각 정의하였다.
하지만 이진트리에서는 노드가 위치할 수 있는 곳에 노드가 존재하지 않아도, 공집합 노드가 존재하는 것으로 간주하고 공집합 노드도 이진트리를 판단하는 데 있어서 노드로 인정받는다.
- 따라서 자식 노드가 하나도 없는 노드도 그 자체로 이진트리이기 때문에 별도로 이진트리를 표현하기 위한 구조체는 구현하지 않아도 된다.
그럼 헤더파일에 선언된 함수의 기능을 정리해 보자.
- BData GetNodeData(BNode node) / void SetNodeData(BNode node, BData data)
- 노드에 저장된 데이터를 반환하거나, 노드에 데이터를 저장한다.
- BNode GetLeftSubTree(BNode node) / BNode* GetRightSubTree(BNode* node)
- 파라미터로 넘어온 노드의 왼쪽/오른쪽 서브 트리의 주소 값을 반환한다.
- void MakeLeftSubTree(BNode main, BNode sub)
- 왼쪽 서브 트리를 연결한다.
- void MakeRightSubTree(BNode main, BNode sub)
- 오른쪽 서브 트리를 연결한다.
3. 이진트리의 구현
이진 트리의 구현은 의외로 쉽다. 코드도 그렇게 길지 않으니 천천히 살펴보는 것만으로도 충분히 이해가 가능하다.
#include "BinaryTree.h"
BData GetNodeData(BNode* node)
{
if(node != nullptr && node->data != 0)
return node->data;
return BData();
}
void SetNodeData(BNode* node, BData data)
{
if (node != nullptr)
node->data = data;
}
BNode* GetLeftSubTree(BNode* node)
{
return (node != nullptr && node->left != nullptr) ? node->left : nullptr;
}
BNode* GetRightSubTree(BNode* node)
{
return (node != nullptr && node->right != nullptr) ? node->right : nullptr;
}
void MakeLeftSubTree(BNode* main, BNode* sub)
{
if (main == nullptr)
return;
if (main->left != nullptr)
delete main->left;
main->left = sub;
}
void MakeRightSubTree(BNode* main, BNode* sub)
{
if (main == nullptr)
return;
if (main->right != nullptr)
delete main->right;
main->right = sub;
}
[BinaryTree.cpp]
코드를 잘 보면 문제가 생길 만한 부분이 존재한다. 아래 글을 보기 전에 먼저 어떤 함수에서 어떤 부분이 문제가 생길지 생각해 보자.
void MakeLeftSubTree(BNode* main, BNode* sub)
{
if (main == nullptr)
return;
if (main->left != nullptr)
delete main->left;
main->left = sub;
}

문제는 MakeLeftSubTree() 함수와 MakeRightSubTree() 함수에서 발생한다.
한 번의 delete가 전부이기 때문에, 삭제할 서브 트리가 하나의 노드로 이뤄져 있다면 문제없지만, 그렇지 않다면 메모리 누수로 이어진다.
따라서 둘 이상의 서브 트리를 구성하는 모든 노드를 대상으로 delete를 해야 한다. 이렇게 모든 노드를 방문하는 것을 가리켜 “순회”라고 하는데, 데이터가 나란히 있는 다른 자료구조와 달리 트리는 별도의 방법이 필요하다.
순회를 살펴보기 전에 이진트리 사용 예제인 Main함수를 살펴보자.
#include <iostream>
#include "BinaryTree.h"
using namespace std;
int main()
{
auto node1 = new BNode;
auto node2 = new BNode;
auto node3 = new BNode;
auto node4 = new BNode;
SetNodeData(node1, 1);
SetNodeData(node2, 2);
SetNodeData(node3, 3);
SetNodeData(node4, 4);
MakeLeftSubTree(node1, node2); // node1의 왼쪽 서브 트리는 node2
MakeRightSubTree(node1, node3); // node1의 오른쪽 서브 트리는 node3
MakeLeftSubTree(node2, node4); // node2의 왼쪽 서브 트리는 node4
cout << "Node1의 왼쪽 자식 노드 데이터 : "
<< GetNodeData(GetLeftSubTree(node1)) << endl;
cout << "Node1의 왼쪽 자식 노드의 왼쪽 자식 노드의 데이터 : "
<< GetNodeData(GetLeftSubTree(GetLeftSubTree(node1))) << endl;
return 0;
}
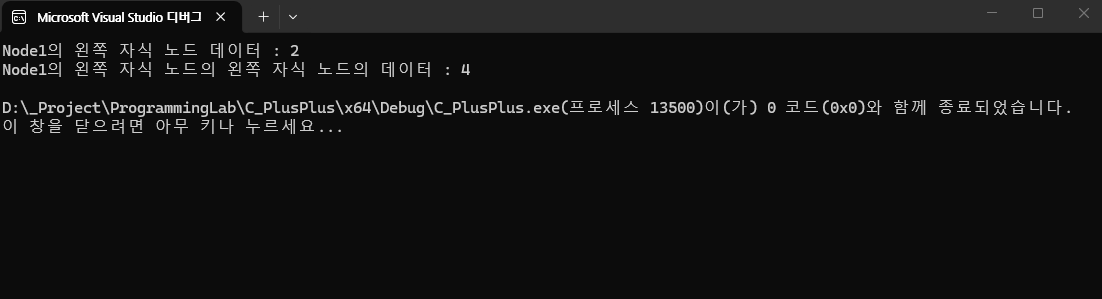
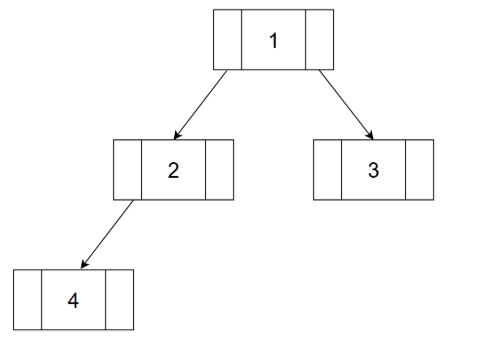
위 Main 함수를 통해 형성되는 이진트리의 구조는 위와 같다. 1이 저장된 노드의 왼쪽 자식 노드와, 그 자식 노드의 왼쪽 자식 노드를 출력했을 때, 위 구조처럼 출력이 되는것을 확인할 수 있다.
■ 이진 트리의 순회(Traversal)
아까 트리를 구현함에 있어서 “재귀”를 이해해야 한다고 했는데, 이진트리를 순회할 때 재귀 방식이 사용된다.
무조건 재귀 방식을 사용하는 것은 아니고, 스택이나 큐를 사용해 반복문 방식으로도 구현한다.
트리를 순회하는 방식에는 크게 3가지 방식이 존재한다.
- 전위 순회(Preorder Traversal) : 루트를 먼저 방문. (루트 → 왼쪽 → 오른쪽)
- 중위 순회(Inorder Traversal) : 루트를 중간에 방문. (왼쪽 → 루트 → 오른쪽)
- 후위 순회(Postorder Traversal) : 루트 노드를 마지막에 방문. (왼쪽 → 오른쪽 → 루트)
1. 순회의 재귀적 표현
위 3가지의 방식 모두 재귀적으로 구현만 하면 문제는 해결된다. 재귀가 끼어있어서 감을 잡기 힘들 수도 있는데, 먼저 중위 순회를 진행하는 함수를 살펴보자.

서브 트리라고 해서 순회의 방법이 달라지는 것은 아니다. 간단하게 전체를 순회하는 함수는 아래와 같이 정의할 수 있다.
void InorderTraverse(BNode* node)
{
if (node == nullptr)
return;
// 왼쪽 서브트리 부터 탐색
InorderTraverse(node->left);
cout << "Node Data : " << node->data << endl;
// 오른쪽 서브트리 탐색
InorderTraverse(node->right);
}
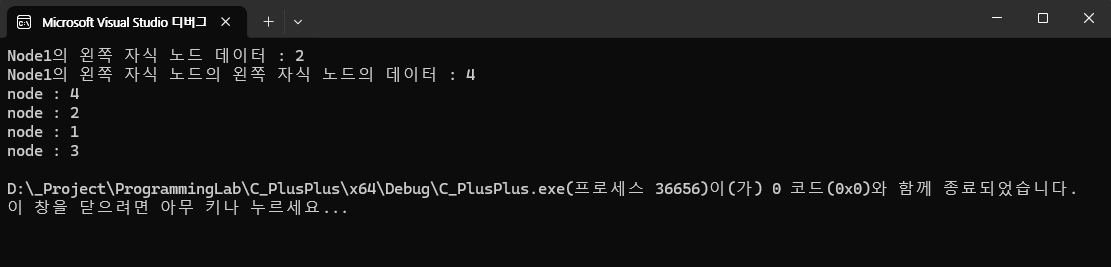
일단은 트리의 전체 노드를 순회하며 저장된 데이터를 출력하는 함수를 작성하였다. 재귀의 탈출 조건은 자식이 더 이상 존재하지 않는 경우(node == nullptr인 경우)가 바로 탈출 조건이다.
Main에서도 해당 함수를 호출하면, 왼쪽 서브트리의 단말 노드부터 거슬러 올라가 루트를 거쳐 오른쪽 서브트리로 넘어가는 것을 확인할 수 있다.
void PreorderTraverse(BNode* node)
{
if (node == nullptr)
return;
cout << "node : " << node->data << endl;
PreorderTraverse(node->left);
PreorderTraverse(node->right);
}
void PostorderTraverse(BNode* node)
{
if (node == nullptr)
return;
PostorderTraverse(node->left);
PostorderTraverse(node->right);
cout << "node : " << node->data << endl;
}
[전위, 후위 순회 방식]
중위 순회 방식과 동일하게 전위와 후위 순회 방식도 구현할 수 있다. 차이는 루트 노드를 방문하는 문장이 삽입된 위치이다.
2. 노드의 방문 목적을 자유롭게 구성하기
노드를 순회하는 데 있어서 목적은 데이터 출력이 전부가 아니다. 따라서 함수 포인터를 사용해서 노드를 방문했을 때 할 일을 결정해 보자.
// **BinaryTree.h**
void InorderTraverse(BNode* node, void (*visit)(BNode*));
// **BinaryTree.cpp**
void InorderTraverse(BNode* node, void (*visit)(BNode*))
{
if (node == nullptr)
return;
// 왼쪽 서브트리 부터 탐색
InorderTraverse(node->left, visit);
visit(node);
// 오른쪽 서브트리 탐색
InorderTraverse(node->right, visit);
}
[함수 포인터 추가]
함수의 주소 값을 매개변수 visit를 통해 전달받도록 변경하였다. 그리고 이 함수를 기반으로 노드의 방문은 다음과 같이 처리되도록 변경하였다.
- visit(node) ← 노드의 방문
즉, 매개변수 visit에 전달되는 함수에 따라 노드의 방문결과가 결정되는 것이다.
#include <iostream>
#include "BinaryTree.h"
using namespace std;
void PrintNodeData(BNode* node);
int main()
{
auto node1 = new BNode;
auto node2 = new BNode;
auto node3 = new BNode;
auto node4 = new BNode;
SetNodeData(node1, 1);
SetNodeData(node2, 2);
SetNodeData(node3, 3);
SetNodeData(node4, 4);
MakeLeftSubTree(node1, node2); // node1의 왼쪽 서브 트리는 node2
MakeRightSubTree(node1, node3); // node1의 오른쪽 서브 트리는 node3
MakeLeftSubTree(node2, node4); // node2의 왼쪽 서브 트리는 node4
cout << "중위 순회 결과" << endl;
InorderTraverse(node1, PrintNodeData);
cout << endl;
return 0;
}
void PrintNodeData(BNode* node)
{
cout << "Data : " << GetNodeData(node) << endl;
}
[Main.cpp]
Main 함수에서도 위와 같이 코드를 수정해 주면, 함수 포인터를 통해 중위 순회에서 방문 목적을 지정해 줄 수 있다.
3. 순회를 통한 노드의 삭제
앞서 MakeLeftSubTree() 함수와 MakeRightSubTree() 함수의 문제에 대해 살펴봤으니, 구현한 순회 함수를 통해 문제를 해결해 보자.
- 서브 트리의 자식 노드들까지 순회를 통해 모두 제거.

상황을 다시 한번 살펴보면, 1번 노드의 왼쪽 자식인 2번 노드를 삭제해야 한다고 해보자. 그럼 2번 노드의 모든 자식 노드들을 순회하며 삭제해야 할 것이다.
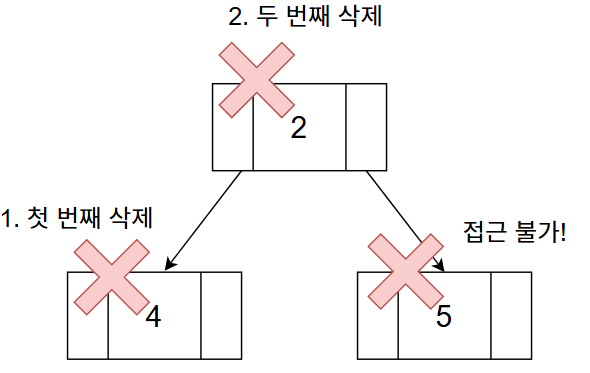
하지만 여기서 살펴봐야 할 점이 있는데, 중위 순회의 경우 왼쪽 → 루트 → 오른쪽의 순서로 순회한다.
왼쪽 노드를 방문하고 자식 노드가 더 이상 없으면 왼쪽 노드를 삭제한 뒤, 루트 노드가 삭제된다. 이렇게 되면 루트 노드가 삭제되어 루트 노드의 오른쪽 노드는 더 이상 접근할 수 없다.
void MakeLeftSubTree(BNode* main, BNode* sub)
{
if (main == nullptr)
return;
if (main->left != nullptr)
{
PostorderTraverse(main->left, [](BNode* node) { delete node; });
main->left = nullptr;
}
main->left = sub;
}
void MakeRightSubTree(BNode* main, BNode* sub)
{
if (main == nullptr)
return;
if (main->right != nullptr)
{
PostorderTraverse(main->right, [](BNode* node) { delete node; });
main->right = nullptr;
}
main->right = sub;
}
[하위 노드의 모든 노드 삭제]
위와 같은 문제를 방지하기 위해 후위 순회를 사용하여 자식 노드부터 차례대로 삭제한 뒤, 마지막에 부모 노드를 삭제하도록 구현하였다.
PostorderTraverse(main->left, [](BNode* node) { delete node; });
[](BNode* node) { delete node; }는 이름이 없는 익명 함수(람다)로, 방문한 노드를 즉시 delete 하도록 정의된 콜백 함수이다.
#include <iostream>
#include "BinaryTree.h"
using namespace std;
void PrintNodeData(BNode* node);
int main()
{
auto node1 = new BNode;
auto node2 = new BNode;
auto node3 = new BNode;
auto node4 = new BNode;
SetNodeData(node1, 1);
SetNodeData(node2, 2);
SetNodeData(node3, 3);
SetNodeData(node4, 4);
MakeLeftSubTree(node1, node2); // node1의 왼쪽 서브 트리는 node2
MakeRightSubTree(node1, node3); // node1의 오른쪽 서브 트리는 node3
MakeLeftSubTree(node2, node4); // node2의 왼쪽 서브 트리는 node4
cout << "중위 순회 결과" << endl;
InorderTraverse(node1, PrintNodeData);
cout << endl;
// 노드 1의 왼쪽 자식 교체
auto node5 = new BNode;
SetNodeData(node5, 5);
MakeLeftSubTree(node1, node5);
cout << "중위 순회 결과" << endl;
InorderTraverse(node1, PrintNodeData);
cout << endl;
return 0;
}
void PrintNodeData(BNode* node)
{
cout << "Data : " << GetNodeData(node) << endl;
}

이렇게 트리의 구현과, 트리를 순회하는 재귀 호출 함수를 작성해 보았다. 다음에는 수식 트리를 사용해 계산기 프로그램을 만들어보자.
'C++ > 자료구조' 카테고리의 다른 글
| [C++, 자료구조] 덱(Deque) (1) | 2025.12.22 |
|---|---|
| [C++, 자료구조] 큐(Queue) (0) | 2025.12.22 |
| [C++, 자료구조] stack의 응용 : 계산기 프로그램 (0) | 2025.11.11 |
| [C++, 자료구조] 스택(Stack) (1) | 2025.11.11 |
| [C++, 자료구조] 양방향 연결 리스트(Doubly Linked List) (0) | 2025.10.23 |